As Senior Director of DevOps, my primary job is deploying the products we develop into our various environments. Plus, I ensure they are reliable and resilient.
As Senior Director of DevOps, my primary job is deploying the products we develop into our various environments. Plus, I ensure they are reliable and resilient.
This makes me extra proud to say SocketLabs has 5-9s of uptime. But the concept of 5-9s isn’t something most people can wrap their heads around.
What does “5-9s” mean?
Simply put, 5-9s means our platform is available for requests 99.999% of the time. See? Five nines, or 5-9s. Some people say they have 4-9s or 3-9s of uptime, but what does this equate to in terms of total downtime duration?
Here are the various durations of allowable downtime for different availability:
| Availability | Downtime Per Year | Downtime Per Month |
| 99.999% | 0h 05m 15s | 0h 00m 26s |
| 99.990% | 0h 52m 33s | 0h 04m 23s |
| 99.900% | 8h 45m 36s | 0h 43m 48s |
| 99.000% | 15h 36m 00s | 1h 18m 00s |
Wow.
You can see at 99.999% availability, there is little room for error. We achieve this by architecting our platform to be as resilient as possible. To do this, we use multiple load-balanced, geographically diverse endpoints, and we use DNS round-robin techniques to distribute load on our platform.
For our messaging processing operations, our two-tier architecture allows us to be highly available to our customers for receiving mail and handling injection API requests. As mail is queued on our receivers, we have further control over where the mail is routed for outbound delivery. For our enterprise customers with multiple outbound IP addresses, we can reroute mail through alternate availability zones for deliverability or technical issues.
This is what our architecture looks like at a high level:
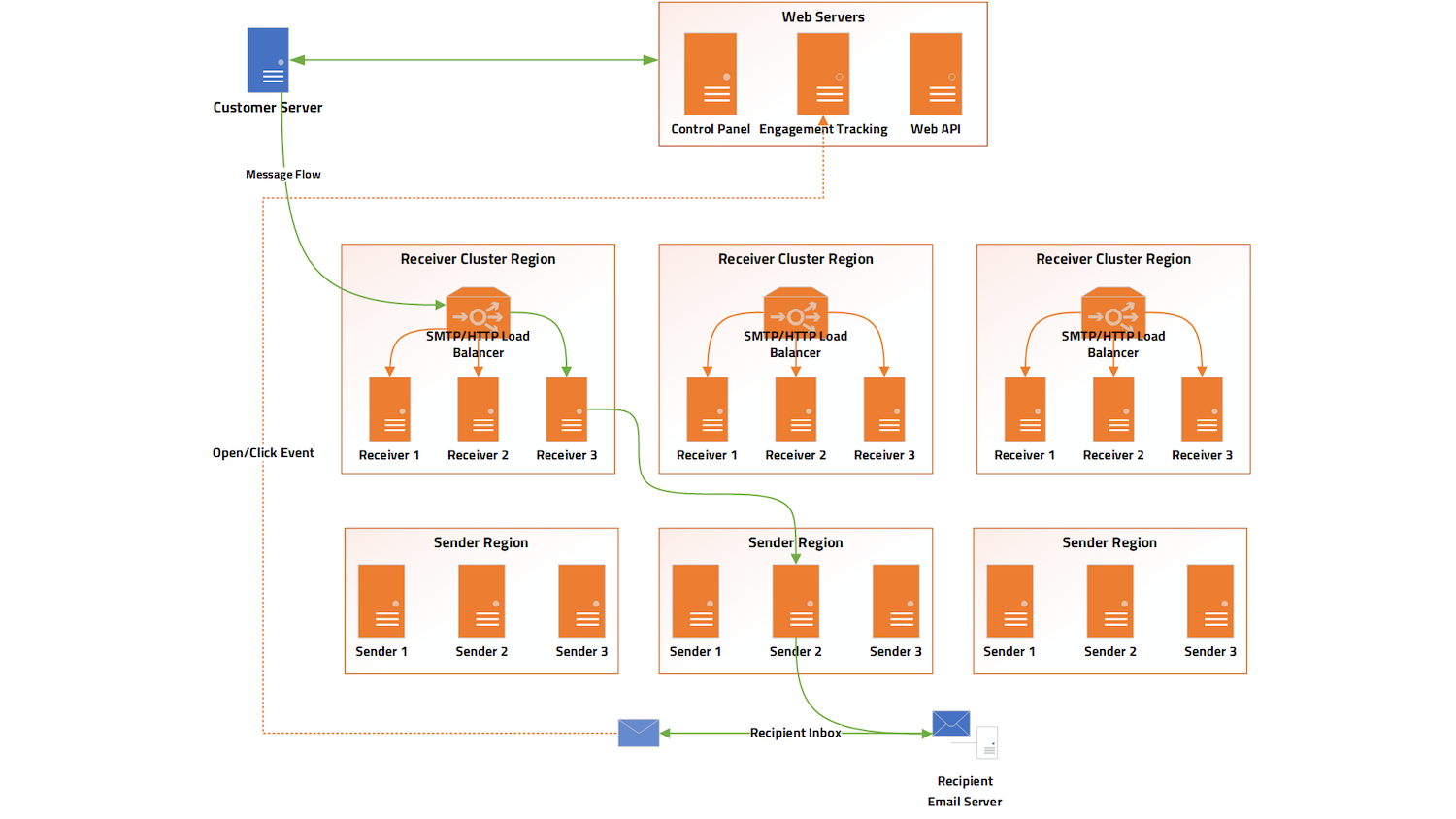
This architecture’s added benefit is that we can remove infrastructure during periods of maintenance so our customers are not affected. If an availability zone is under heavy load or experiencing technical issues, we can redistribute traffic to unaffected regions. This also allows us to redirect traffic when we detect issues beyond our control, such as internet backbone routing issues or regional outages. A lot of this happens automatically without any human intervention needed.
To verify all this, we use a service from uptime.com. They perform continuous testing of our endpoints from all around the world. We test our two main endpoints from five regions every minute. And these tests aren’t simple ping tests. Nope. These tests are functional tests: For our SMTP endpoint smtp.socketlabs.com, uptime.com performs an SMTP protocol test, and for our Injection API endpoint inject.socketlabs.com, we perform a test message injection by calling our API.
What was our final result for 2021? Our two messaging endpoints were our highest priority missions, and we achieved a 100% uptime for the entire year.
No, seriously. We did. We. Did. That.
Ok, I know 100% is technically not “5-9s,” but we did have some brief disruptions on our secondary endpoints, such as our control panel and tracking endpoints, which came in at 99.999% uptime. Our worst performing endpoint was our Platform API, which was at 99.992% uptime. Not bad!
In the future we will be expanding our goals by focusing on end-to-end performance for our messaging platform and improving latency and response times. Plus, we’re SOC-2 Type 2 certified, further solidifying our reputation as a trusted vendor. It’s a lot of hard work, but maintaining high availability is one of our top priorities and will continue to be.
If you want more details about our uptime you can view our entire historical uptime report at https://skt.to/uptime-report. You can also view information about our current platform status or any scheduled maintenance by going to https://status.socketlabs.com.